基于VGG16识别猫狗图片
AI发展如火如荼,在图像识别、语音识别、推荐等方面应用越来越广,新时代的IT不掌握AI就不完整
# 人工智能技术大的方向有四个:1模式识别,比如图像识别、视频分析;2情感识别,比如声纹识别;3计算机视觉,比如人脸识别;4推荐系统,比如订单排序;[SEP]对于机器学习ai和深度学习可以先看johnsiracusa的博士论文,或者wendellbenedict的论文《onairelationships》,就可以对人工智能技术有个总体了解。
VGG16是什么
VGG16网络是14年牛津大学计算机视觉组和Google DeepMind公司研究员一起研发的深度网络模型。VGG16模型很好的适用于分类和定位任务,其名称来自牛津大学几何组(Visual Geometry Group)的缩写。VGG16网络取得了ILSVRC 2014比赛分类项目的第2名,定位项目的第1名。
根据卷积核的大小核卷积层数,VGG共有6种配置,分别为A、A-LRN、B、C、D、E,其中D和E两种是最为常用的VGG16和VGG19。
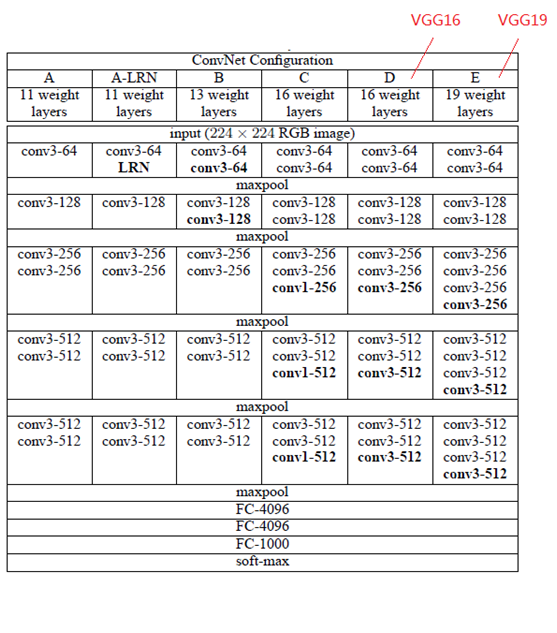
里面有很多专业术语,解释在下面,暂时不理解也没关系,大致知道什么意思就行了。介绍结构图:
- conv3-64 :是指第三层卷积后维度变成64,同样地,conv3-128指的是第三层卷积后维度变成128;
- input(224x224 RGB image) :指的是输入图片大小为224 * 244的彩色图像,通道为3,即224 * 224 * 3;
- maxpool :是指最大池化,在vgg16中,pooling采用的是2*2的最大池化方法(如果不懂最大池化,下面有解释);
- FC-4096 :指的是全连接层中有4096个节点,同样地,FC-1000为该层全连接层有1000个节点;
- padding:指的是对矩阵在外边填充n圈,padding=1即填充1圈,5X5大小的矩阵,填充一圈后变成7X7大小;
- 最后补充,vgg16每层卷积的滑动步长stride=1,padding=1,卷积核大小为333;
从上图可以看出,VGGNet有5段卷积层,每一段内有2个或3个卷积层,每段结尾连接一个最大池化层用于缩小图片尺寸;各段内部的卷积核数量一样,越靠近全连接层卷积核数量越多。
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
VGG网络的结构非常一致,从头到尾全部使用的是3x3的卷积和2x2的max pooling。
如果你想看到更加形象化的VGG网络,可以使用经典卷积神经网络(CNN)结构可视化工具来查看高清无码的VGG网络。
VGG优缺点
VGG优点
- VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。
- 几个小滤波器(3x3)卷积层的组合比一个大滤波器(5x5或7x7)卷积层好:
- 验证了通过不断加深网络结构可以提升性能。
VGG缺点
- VGG耗费更多计算资源,并且使用了更多的参数(这里不是3x3卷积的锅),导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层。VGG可是有3个全连接层啊!
PS:有的文章称:发现这些全连接层即使被去除,对于性能也没有什么影响,这样就显著降低了参数数量。
注:很多pretrained的方法就是使用VGG的model(主要是16和19),VGG相对其他的方法,参数空间很大,最终的model有500多m,AlexNet只有200m,GoogLeNet更少,所以train一个vgg模型通常要花费更长的时间,所幸有公开的pretrained model让我们很方便的使用。
TensorFlow VGG-16预训练模型
https://zhuanlan.zhihu.com/p/160086442
参考博文:https://blog.csdn.net/daydayup_668819/article/details/70225244
在我们的实际项目中,一般不会直接从第一层直接开始训练,而是通过在大的数据集上(如ImageNet)训练好的模型,把前面那些层的参数固定,在运用到我们新的问题上,修改最后一到两层,用自己的数据去微调(finetuning),一般效果也很好。
所谓finetuning,就是说我们针对某相似任务已经训练好的模型,比如CaffeNet,VGG-16,ResNet等,再通过自己的数据集进行权重更新,如果数据量比较小,可以只更新最后一层,其他层的权重不变,如果数据量中等,可以训练后面几层,如果数据量很大,那OK,直接从头训练,只不过花在训练的时间比较多。
在网络训练好之后,只需要forward过程就能做预测,当然,我们也可以直接把这个网络当成一个feature extractor 来用,可以直接用任何一层的输出作为特征,根据R-CNN对AlexNet的实验结果,如果不做 fine-tuning,pool5和fc6和fc7的特征效果并没有很强的提升,所以如果直接用作feature extractor,直接用pool的最后一层输出就OK。
VGG-16是一种深度卷积神经网络模型,16表示其深度。模型可以达到92.7%的测试准确度,它的数据集包括1400万张图像,1000个类别。
我们想做什么
直接使用pretrained的VGG16的model,再结合MLP快速训练出我们的猫狗识别模型
第一步:加载图片
# load the data
from keras.preprocessing.image import load_img, img_to_array
img_path = 'doga2.jpg'
img = load_img(img_path,target_size=(224,224))
img = img_to_array(img)
type(img)
img.shape
这里用到了Keras。Keras的官网这么介绍:
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK, 或者 Theano 作为后端运行。Keras 的开发重点是支持快速的实验。能够以最小的时延把你的想法转换为实验结果,是做好研究的关键。
默认的后端是TensorFlow。
因为是刚入门,所以还不很清楚Keras是不是目前比较新的,和pytorch等是什么关系。从网上看到如下的比较。但,不管怎么样,先用着再说。
- Tensorflow更倾向于工业应用领域,适合深度学习和人工智能领域的开发者进行使用,具有强大的移植性。
- Pytorch更倾向于科研领域,语法相对简便,利用动态图计算,开发周期通常会比Tensorflow短一些。
- Keras因为是在Tensorflow的基础上再次封装的,所以运行速度肯定是没有Tensorflow快的;但其代码更容易理解,容易上手,用户友好性较强。
另外,VGG16处理的图片都是224 * 224的。这点也很重要。如果原图不是,需要调整为这个像素。这就是Keras比较方便的地方,load_img函数中直接使用target_size就可以直接进行调整。
img_to_array没什么好说的,img对象转换为numpy的array。这时候的shape是(224, 224, 3)。
第二步:导入VGG16模型
from keras.applications.vgg16 import VGG16
from keras.applications.vgg16 import preprocess_input
import numpy as np
#我们构建的模型会将VGG16顶层去掉,只保留其余的网络
# 结构。这里用include_top = False表明我们迁移除顶层以外的其余网络结构到自己的模型中
model_vgg = VGG16(weights='imagenet',include_top=False)
x = np.expand_dims(img,axis=0)
x = preprocess_input(x)
print(x.shape)
#(1, 224, 224, 3)
这里要注意include_top参数,false的时候是去除掉顶层,即全连接层。这样导入的模型就只能做特征提取。
weights=’imagenet’,不是很理解,好像是把imagenet网络训练结果的权重值取出来。
看资料,导入VGG模型的时候也可以指定像素:
model_vgg = VGG16(include_top=False, weights='imagenet', input_shape=(48, 48, 3))
没有实验过,不知道是否可行。
百度了一下imagenet:
# ImageNet是一种数据集,而不是神经网络模型。斯坦福大学教授李飞飞为了解决机器学习中过拟合和泛化的问题而牵头构建的数据集。该数据集从2007年开始手机建立,直到2009年作为论文的形式在CVPR 2009上面发布。直到目前,该数据集仍然是深度学习领域中图像分类、检测、定位的最常用数据集之一。
# 基于ImageNet有一个比赛,从2010年开始举行,到2017年最后一届结束。该比赛称为ILSVRC,全称是ImageNet Large-Scale Visual Recognition Challenge,每年举办一次,每次从ImageNet数据集中抽取部分样本作为比赛的数据集。ILSVRC比赛包括:图像分类、目标定位、目标检测、视频目标检测、场景分类。在该比赛的历年优胜者中,诞生了AlexNet(2012)、VGG(2014)、GoogLeNet(2014)、ResNet(2015)等耳熟能详的深度学习网络模型。“ILSVRC”一词有时候也用来特指该比赛使用的数据集,即ImageNet的一个子集,其中最常用的是2012年的数据集,记为ILSVRC2012。因此有时候提到ImageNet,很可能是指ImageNet中用于ILSVRC2012的这个子集。ILSVRC2012数据集拥有1000个分类(这意味着面向ImageNet图片识别的神经网络的输出是1000个),每个分类约有1000张图片。这些用于训练的图片总数约为120万张,此外还有一些图片作为验证集和测试集。ILSVRC2012含有5万张图片作为验证集,10万张图片作为测试集(测试集没有标签,验证集的标签在另外的文档给出)。
第三步:特征提取
#特征提取
features = model_vgg.predict(x)
print(features.shape)
#(1, 7, 7, 512)
#flatten
features = features.reshape(1,7*7*512)
print(features.shape)
#(1, 25088)
这里直接调用模型的predict方法进行特征提取。因为模型导入的时候去掉了最顶层,即全连接层,所以这里的predict只能做特征提取,而不能做真正的预测。
特征提取后,得到的nparray再拉平,就可以作为后续MLP模型的输入。
第四步,图片可视化(可选)
# visualize the data
%matplotlib inline
from matplotlib import pyplot as plt
fig = plt.figure(figsize=(5,5))
img = load_img(img_path, target_size = (224,224))
plt.imshow(img)
图片画出来看看,人还都是相信看到的东西。
第五步:批量预处理图片
上面的四步,只是探索了一张图片的处理,下面需要整理好程序,对所有收集的图片进行批量预处理:
#load image and preprocess it with vgg16 structure
#
from keras.preprocessing.image import img_to_array, load_img
from keras.applications.vgg16 import VGG16
model_vgg = VGG16(weights='imagenet',include_top=False)
#difine a method to load and preprocess the image
def modelProcess(img_path,model):
img = load_img(img_path,target_size=(224,224))
img = img_to_array(img)
x = np.expand_dims(img,axis=0)
x = preprocess_input(x)
x_vgg = model_vgg.predict(x)
x_vgg = x_vgg.reshape(1,25088)
return x_vgg
#list file name of the training datasets
import os
folder = "./valid/cats"
dirs = os.listdir(folder)
#generate path for the images
img_path = []
for i in dirs:
if os.path.splitext(i)[1] == '.jpg':
img_path.append(i)
img_path = [folder+"//"+i for i in img_path]
#preprocess multiple images
features1 = np.zeros([len(img_path),25088])
for i in range(len(img_path)):
feature_i = modelProcess(img_path[i],model_vgg)
print('preprocessed:',img_path[i])
features1[i] = feature_i
folder = "./valid/dogs"
dirs = os.listdir(folder)
#generate path for the images
img_path = []
for i in dirs:
if os.path.splitext(i)[1] == '.jpg':
img_path.append(i)
img_path = [folder+"//"+i for i in img_path]
#preprocess multiple images
features2 = np.zeros([len(img_path),25088])
for i in range(len(img_path)):
feature_i = modelProcess(img_path[i],model_vgg)
print('preprocessed:',img_path[i])
features2[i] = feature_i
#lable the results
print(features1.shape, features2.shape)
#(1000, 25088) (1000, 25088)
y1 = np.zeros(1000)
y2 = np.ones(1000)
#generate the training data
x = np.concatenate((features1,features2),axis=0)
y = np.concatenate((y1,y2),axis=0)
y = y.reshape(-1,1)
print(x.shape,y.shape)
#(2000, 25088) (2000, 1)
这里分别处理了猫和狗两组图片,各1000张。
第六步:分离样本
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=50)
print(x_train.shape,x_test.shape,x.shape)
#(1400, 25088) (600, 25088) (2000, 25088)
30%的比例分配测试数据集,70%为训练数据集。
第七步:配置后续MLP模型
#set up the mlp model
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(units=10,activation="relu",input_dim=25088))
model.add(Dense(units=1,activation="sigmoid"))
model.summary()
'''
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 10) 250890
_________________________________________________________________
dense_2 (Dense) (None, 1) 11
=================================================================
Total params: 250,901
Trainable params: 250,901
Non-trainable params: 0
'''
MLP就只配置了两层,一层Relu,10个神经元,一层sigmoid,1个神经元。
Sigmoid在二分类场景中比较适用。这个案例是做猫狗区分,正好合适。
第八步:编译模型和训练模型
#configure the model
#model.compile(optimizer='adam',loss = 'binary_crossentropy',metrics=['accurary'])
#configure the model
from tensorflow import optimizers
# model.compile(loss='binary_crossentropy',
# optimizer=optimizers.RMSprop(learning_rate=1e-4),
# metrics=['acc'])
model.compile(loss='binary_crossentropy',
optimizer=optimizers.Adam(),
metrics=['accuracy'])
model.fit(x_train,y_train,epochs=50)
'''
Epoch 1/50
44/44 [==============================] - 1s 6ms/step - loss: 0.8021 - accuracy: 0.7393
Epoch 2/50
44/44 [==============================] - 0s 6ms/step - loss: 0.1708 - accuracy: 0.9271
...
Epoch 49/50
44/44 [==============================] - 0s 6ms/step - loss: 0.0019 - accuracy: 0.9993
Epoch 50/50
44/44 [==============================] - 0s 5ms/step - loss: 0.0019 - accuracy: 0.9993
'''
循环50次,准确率就到了99.93%。还是相当可以的。
第九步:计算训练集上的准确率
#accuracy on the training data
from sklearn.metrics import accuracy_score
predict_x = model.predict(x_train)
print(predict_x)
y_train_predict=np.argmax(predict_x,axis=1)
print(y_train_predict)
print(y_train)
accuracy_train = accuracy_score(y_train,y_train_predict)
print(accuracy_train)
这里程序有点问题,原程序引用的是model.predict_classes做预测,而在最新版本里面,这个函数被去掉了,只能用model.predict,所以引起了错误。具体原因还不是很清楚。上一步里面的99.93%应该是可信的。
另外,这里也可以同样做测试数据集上的准确率计算。因为程序问题,就省略了。
第十步:网络图片验证
模型都搞好了,可以拿网络上的图片来验证,随便百度些猫狗图片,下载下来,保存,然后让模型识别一下:
img_path = 'cata2.jpg'
img = load_img(img_path,target_size=(224,224))
img = img_to_array(img)
x = np.expand_dims(img,axis=0)
x = preprocess_input(x)
#特征提取
features = model_vgg.predict(x)
features = features.reshape(1,7*7*512)
result = model.predict(features)
print(result)
#[[0.]]
识别结果是0,到底是什么含义呢?可以通过这个看看:
training_set.class_indices
# valid_set.class_indices
#{'cats': 0, 'dogs': 1}
这里可以看到,0就是猫,1就是狗。
网上下载的图片,基本都能正确识别。模型还是相当给力!
总结
- 这种借鉴别人模型,拿过来微调成为自己模型的方式,好像有个专门的名字,叫迁移学习
- 不练不知道,AI在图像识别方面,真的已经很强大。一台普通的PC,基本都可以胜任一般的识别任务
- 嘉楠耘智的勘智K210芯片,只要十块钱,就可以做一些常用的AI功能:https://www.zhihu.com/question/293015263?ivk_sa=1024320u。K210芯片模组,它基于双核RISC-V 64位处理器,RISC-V是近几年大火的开源指令集架构(ISA),简单且高效。双核的主频高达600MHZ,可以应对各种业务场景及计算任务。硬件浮点指令加速:两个核心均支持双精度指令加速,可使简单的渲染高达100fps。芯片号称1TOPS算力,却只有0.3W的功耗,远远典型设备1W左右的功耗
- 自从阿尔法狗问世,AI突然一日千里。对世界的改造才刚刚开始
- 利用同样的思路,下一步计划用VGG做股市预测,看看有没有戏